| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- #워드프레스
- #라즈베리파이
- 마약
- 이희인
- 안나 까레리나
- #DeepLearning
- 위안부
- 신의 한수
- 박진식
- 아우라가 있는 사람
- 창조적 시선
- #모두를위한딥러닝
- 인생이 묻고
- 빨치산
- 열아홉 편의 겨울 여행과 한 편의 봄 여행
- 진정한 노력
- 원죄형 인간
- #LinearRegression
- hadoop
- 시시콜콜 네덜란드 이야기
- 톨스토이가 답하다
- 시작하세요! 하둡프로그래밍
- 밥 짓기 방법
- 종이의 TV
- 초천재
- 복지천국
- #softmax
- #모두를위한DeepLearning
- 제주
- Airline Delay Count
- Today
- Total
Thing's by Actruce
모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 02 본문
이 포스트는 유명한 홍콩 과기대 김성훈 교수의 "모두를 위한 딥러닝 강좌 시즌 1" 의 내용 중 Convolution Neural Network 이전
특히, 29강 까지의 내용을 중점적으로 리뷰해 보고자 한다. (리뷰01, 02, 03, 04, 05, ...)
CNN 은 별도의 포스트를 구성할 예정이다.
본 포스트의 내용은 김성훈 교수의 Lecture Note 의 내용 및 Lab File 을 활용했음을 알려둔다.
Sung Kim “모두를 위한 딥러닝 강좌 시즌 1”
> 강의 동영상 : https://goo.gl/2cqKLz
> 강의 웹사이트 : http://hunkim.github.io/ml/
> Lecture 슬라이드 : https://goo.gl/4373zL
> Lab 슬라이드 : https://goo.gl/WwCu4U
> 강의 소스코드 : https://goo.gl/T2fuYi
리뷰02 Binomial Logistic Regression (강좌 Lecture 5-1, 5-2) / Multinomial Logistic Regression (강좌 Lecture 6-1, 6-2)
1. Binomial Logistic Regression (이항 로지스틱 회귀분석)
- 이항 로지스틱 회귀분석이라고 하면, 기냐 아니냐의 문제다.
- 맞고 틀리고 처럼 둘 중의 하나를 맞추는 문제로 보면 되는데,
- 활용 분야는 스팸 메일 필터링, 페이스북의 타임라인의 선호 / 비선호 포스트, 신용카드의 사기 감지 등이다.




가설이 바뀌었으므로 Cost Function 도 바뀐다.

조금 복잡한데, 쉽게 설명하면,
실제 y가 1일 때는 H(x) =1 이면 Cost 가 0이 되어야 하고, 실제 y가 0일 때는 H(x) = 0 일 때 Cost 가 0이 되면 된다.

왼쪽에 있는 그림이 -log(H(x)) 인데 H(x) = 1 일 때 cost = 0 으로 수렴하고 (실제 y = 1일 때), 그 반대는 cost 가 무한대이다.
오른쪽에 있는 -log(1-H(x)) 는, H(x) = 0 일 때 cost = 0 으로 수렴하고 (실제 y = 0 일 때), 그 반대는 cost 가 무한대이다.
이런식으로 cost function 을 세우면 각 0, 1 case 에 대해서 cost function 값이 0이 되는 방향으로 학습이 이루어 질 거라고 생각할 수 있다.
조건식을 하나로 합치면 아래와 같은 완성된 형태의 cost function 을 만들 수 있다.

정리해 보면,
Sigmoid 함수는 1 / ( 1 + e^(-z)) 와 같은 형태이며 따라서 가설 함수 H(X) 는 1 / ( 1 + e^(-WX)) 로 표현되는데
이를 2단계로 나눠보면 H_L(x) = WX, z = H_L(x), g(z) = 1 / (1 + e^(-z)) 로 표현할 수 있고, 두 단계의 node 로 표현할 수 있다.
이를 그림으로 나타내면 아래와 같고, 여기서 Sigmoid 는 'S' 표시로 나타낸 node 이다.

2. Multinomial Logistic Regression (다항 로지스틱 회귀분석)
- 단순히 0, 1 로만 표현되던 것에서 Label 이라고 하는 2가지 이상의 분류 Label 을 찾는 모형으로 확장된 형태이다.
- 즉, 여러 특징(feature) 들을 조합하여 분류(classification) 이 가능하다는 것이다.
- Car, Dog, Cat, House 등과 같이 이미지를 분류하여 하나의 대상을 찾아내거나 곤충, 식물, 나무, 포유류, 물고기 등과 같이 여러 특징들을 학습하여 특정 분류를 맞추며 학습하는 방식에 사용된다.
- 여기서 주목해야 할 것은 Feature(특징) 과 Label (분류, Tag) 이다.
- 로지스틱 회귀분석이 중요한 것은 지도학습 Deep Learning 의 결과치는 항상 Label 을 식별하는데 있기 때문이다.

Binomial Logistic Regression 이 둘 중에 하나를 가르는 거였다면 아래 처럼 X, ㅁ 사이에 선을 하나 그으면 된다. 이를 Hyper Plane 이라 부르는데, Multinomial 에서는 상황이 좀 더 복잡해 진다.


즉, 위 그림과 같이 2개 Feature 에 대해서 3개의 Label 로 구분하고 싶다면, 어떻게 해야 할까?
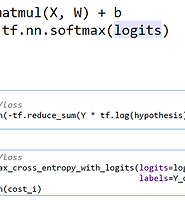
각각의 x1, x2 에 대한 각각의 H(x1, x2) 를 5개 만들어 이를 각각 학습하면 되겠지만, 이는 매우 번거롭다 따라서 5개 학습 데이터를 한꺼번에 학습할 수 있도록 고안된 장치가 필요하다. 즉 3개 Label 각각의 점수 값을 갖고 최종적으로 A일지, B일지, C일지 예측하게 되는데 이게 바로 Softmax 이다.


즉 각 Label 이 나올 점수를 normalize 한 결과로 합이 1.0 이 되도록 조정했다고 보면 된다.
이것도 헷갈리므로 아예 일등만 남겨두기 위해 0.5 기준으로 제일 높은것만 1로 취하고 나머지를 0으로 남겨버린 vector 를
'one-hot' encoding 이라 칭한다.

softmax 를 적용했으므로 cost function 도 맞춰서 바꾼다. 이는 설명하기엔 매우 복잡하므로 강의를 참고 부탁드린다.

Fancy softmax implementation 과 MNIST 예제 실습에 대한 설명은 리뷰03 에 이어집니다.
'IT > Deep Learning' 카테고리의 다른 글
| 모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 06 (0) | 2017.12.17 |
|---|---|
| 모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 05 (0) | 2017.12.17 |
| 모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 04 (0) | 2017.12.17 |
| 모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 03 (0) | 2017.12.17 |
| 모두를 위한 Deep Leaning 강좌(Sung Kim) 리뷰 01 (0) | 2017.12.16 |